WhisperKit
Whisper has pulled the future forward when fast, free and virtually error-free translation and transcription will be ubiquitous. It inspired numerous developers to improve and deploy it with minimal friction and maximum performance.
iPhone 12 mini and iPhone 15 Pro transcribing MKBHD with WhisperKit.
Video not sped up, MKBHD playback at 1.5x because WhisperKit is limited by how fast MKBHD speaks.
We founded Argmax in November 2023 to empower developers and enterprises everywhere to deploy commercial-scale inference workloads on user devices. The fast growing need for Whisper inference in production convinced us to take it on as our first project.
Today, we are excited to open-source the WhisperKit project in beta under MIT license!
Swift package for Whisper inference in Apps in 2 lines of code
Sample App for iOS and macOS on TestFlight
Python tools to optimize and evaluate Whisper on Mac
Our goal with this beta release is to collect developer feedback and reach a stable release candidate in a matter of weeks so WhisperKit can accelerate the productionization of on-device inference!
Call to Action
If you are interested in…
A technical overview: Go ahead and read the rest of this post. Talk to us if you have any feedback.
Extending WhisperKit: Fork and send us a pull request! Here is the Contribution Guide.
Testing WhisperKit in your App: Add it as a package dependency in Xcode and you are ready to deploy with:
If you are just curious, simply install our sample app and join our Discord to ask questions and get acquainted with the Argmax team!
Design Principles
We designed WhisperKit to be
Flexible. You can combine or isolate GPU and Neural Engine utilization. On iPhone, isolated Neural Engine delivers the best energy efficiency and lowest latency. On Mac, concurrent WhisperKit processes can independently utilize GPU and/or Neural Engine to get the highest throughput for batch processing (asitop visuals below). Energy efficiency of isolated Neural Engine inference is yet again relevant for Macs on battery.
Configuration 1: WhisperKit CLI working on 16 audio files utilizing GPU+ANE on a Mac Studio
Configuration 2: Same as above but isolated to ANE
(~14% GPU usage from other processes and green bars overflowing from ANE)
Configuration 3: Same as above but isolated to GPU
Extensible. Modularized into Swift protocols, implementing custom behavior is reduced to individual protocol extensions. We also optimized for time-to-read-the-code so extending WhisperKit is not intimidating. Contribution guide and Roadmap resources are meant to give developers visibility into the timeline for reaching feature complete and stable release candidate stages.
Predictable. We practiced accuracy-driven development where our internal testing infrastructure validates code and model commits on Whisper accuracy evaluation benchmarks comprising librispeech (~2.6k short audio clips, ~5 hours total) and earnings22 (~120 long audio clips, ~120 hours total) datasets. Results of periodic testing are published here. This approach enables us to detect and mitigate quality-of-inference (more on this below) regressions due to code changes in WhisperKit as well as performance and functional regressions from lower levels of the software stack. This helps us improve time-to-detect and time-to-fix most issues with best-effort. Taking it a step further, we offer customer-level SLAs to detect and fix all issues within a maximum time period for specific model and device versions to developers or enterprises.
Auto-deployable. We publish and serve many WhisperKit-compatible models here. WhisperKit includes APIs to list and download specific versions from this server. Our example app is built on this over-the-air deployment infrastructure. Furthermore, developers can leverage whisperkittools (Python toolkit) to publish custom Whisper versions, evaluate them on their own datasets and serve in production.
Performance Focus: Real-time
WhisperKit aims to achieve both lowest latency and highest throughput status on Apple Silicon. For today’s beta release, we deliberately focused on lowest latency first to unlock streaming transcription applications on iPhone, iPad and Mac.
Streaming transcription with real-time speed is extremely challenging because Whisper was not designed to process audio with low latency. Here is what needs to happen before the first token of text is transcribed:
Step 1: Periodically accumulate enough audio to contain an intelligible chunk of speech, e.g. 1-2 seconds. This creates latency regardless of inference speed.
Step 2: Depending on how much historical audio is available, pad or trim the audio to Whisper’s expected clip length, i.e. 30 seconds.
Step 3: Run a 0.6b Transformer Encoder on this 30 second audio clip, or equivalently, 1500 audio tokens.
Step 4: Run 4 special tokens through the 1b Transformer Decoder on the output of Step 3 to configure language and task settings.
Step 5: Finally generate the first text token! Then, keep generating tokens until the special sentinel token is observed.
Total latency of Steps 1 through 4 indicates the time-to-first-token latency. This is a proxy for how snappy the interactive transcription user experience is.
Step 5 is used to measure tokens/second. This is a proxy for how fast the user speech is being transcribed to text.
Steps 1 through 5 are repeated on chunks of audio being recorded live until the transcription session is ended by the user.
Whisper inference is real-time if the total latency of Steps 1 through 5 is less than or equal to the length of the audio chunk. For example, if the transcription pipeline (Steps 1-5) is being invoked every second and it only takes 500 milliseconds for the pipeline to complete, then inference is 2x realtime (aka 0.5 Real-time Factor as the reciprocal metric).
If inference is even slightly slower than real-time, the audio chunks will be enqueued faster than the inference pipeline is able to dequeue them. In that case, the queue will grow and grow until the latency is unacceptable by the user and they stop talking or stale audio gets dropped.
We optimized the Whisper pipeline end-to-end to minimize these undesirable scenarios. Since the real-time designation depends on the pace of speech, we can not certify real-time performance for all possible speech. Instead, we can optimize our pipeline’s performance to maximize the number of text tokens decodable per audio chunk.
In particular, we focus on the openai/whisper-large-v3 variant since this is the most challenging version by far to deploy. We assume a budget of 1 second to transcribe 1 second of speech as a starting point.
Accelerating the Audio Encoder
The audio encoder mentioned in Step 3 was previously optimized by the whisper.cpp project using Core ML following Deploying Transformers on the Apple Neural Engine. Simply put, this work introduces a set of Neural Engine compiler hints as PyTorch code that translate to a high-performing model when converted to Core ML. Given that the Neural Engine compiler is Apple’s private framework, this is a form of black-box optimization to nudge the compiler for increased hardware utilization.
This is a great starting point for accelerating Whisper’s audio encoder and we are happy to see that our previous work is being adopted in various open-source projects.
In WhisperKit, we further improved these compiler hints which yielded an additional 1.86x-2.85x speedup across iPhone 12 through 15 compared to the previous best implementation:
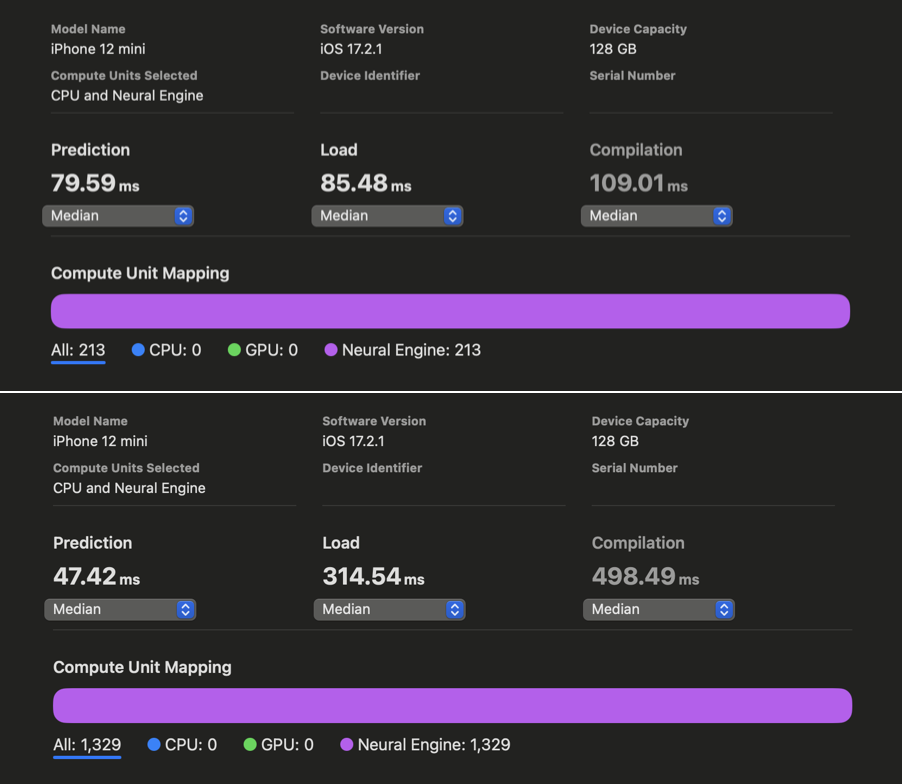
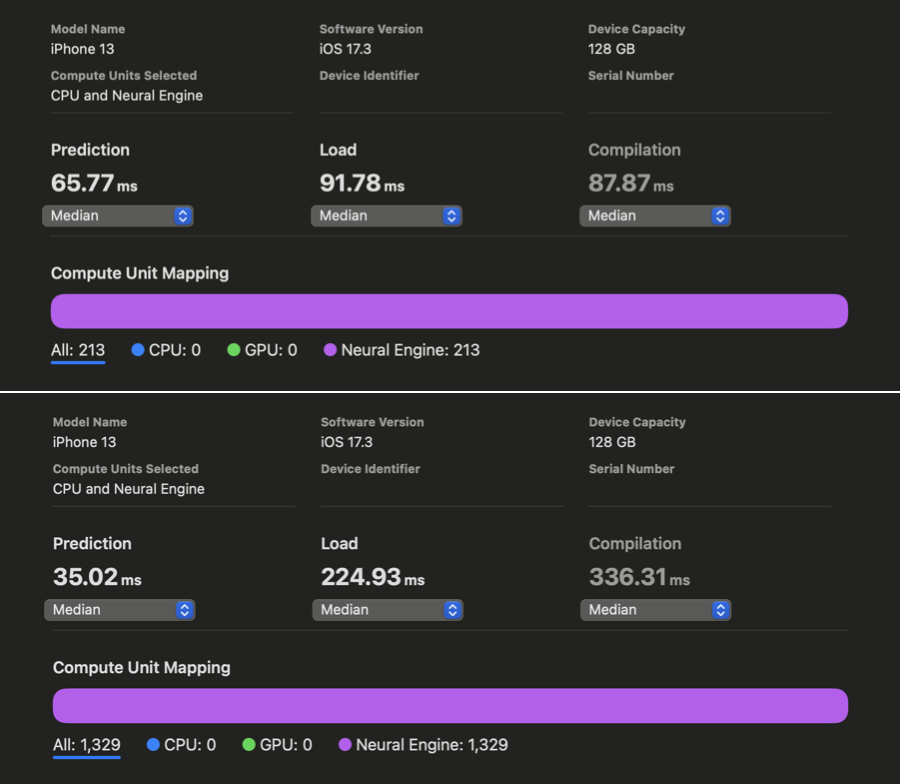
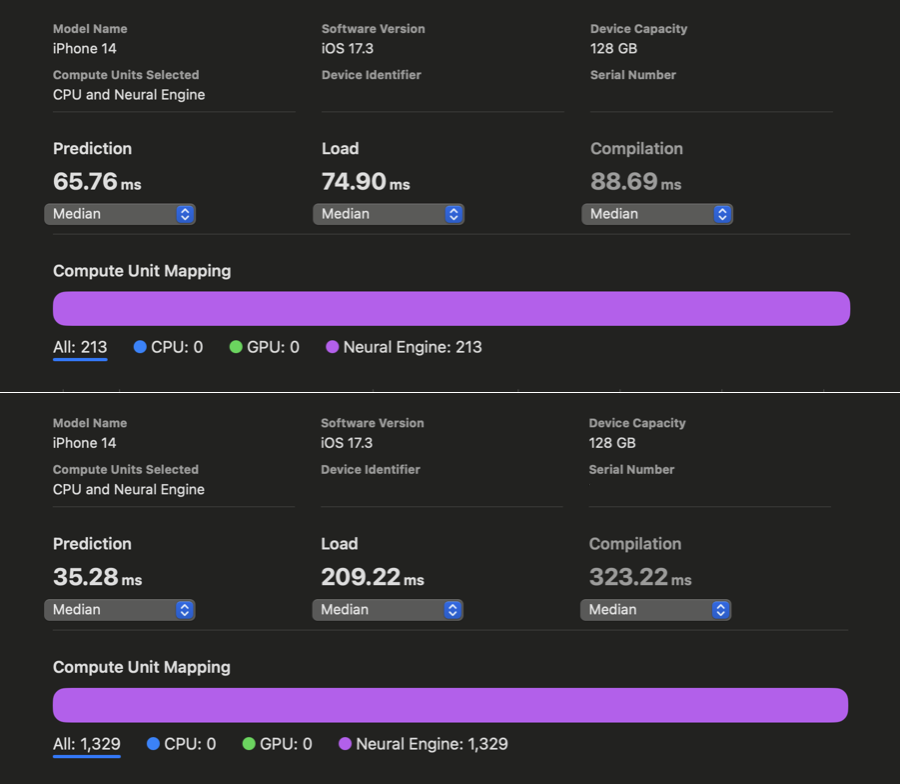
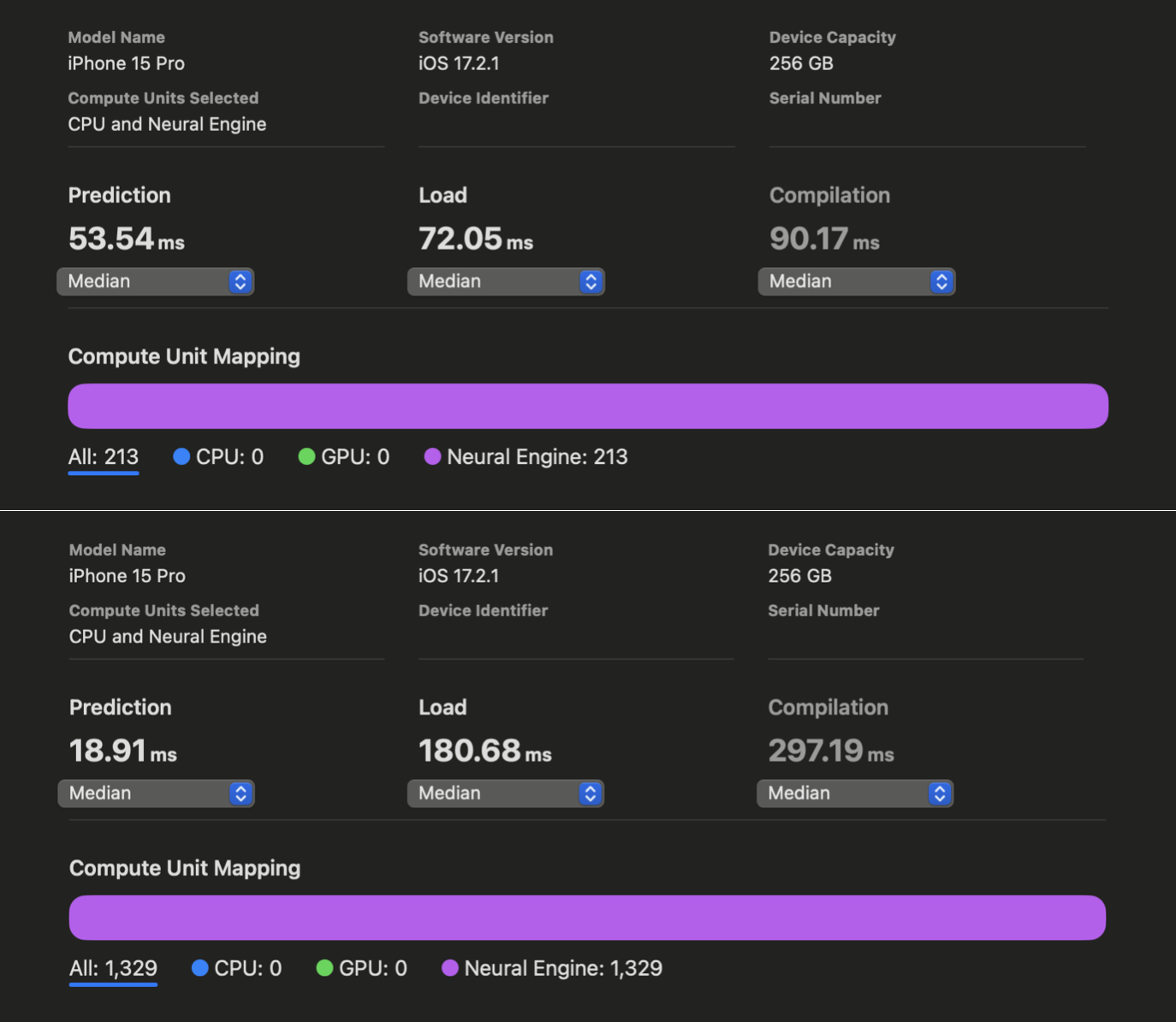
Xcode Core ML Performance Reports above show Prediction latencies before (top) and after (bottom) our improvements applied to openai/whisper-base. Unfortunately, Xcode failed to generate the same reports for the large-v3 variant for iPhone despite multiple retries. Relying on our in-app measurements, we observe a 1.85x speedup (consistent with above results) for openai/whisper-large-v3 on iPhone, achieving as low as ~350 ms of latency! (Down from ~650ms) . This means that we have saved ~300 ms from our 1 second budget to use for decoding additional speech tokens! We have a remaining budget of 650ms and we haven’t started decoding yet..
Note that we added the suffix turbo to models with this optimization in order to distinguish them from our alternative implementation targeting the GPU (talk to us for more details on this).
Accelerating the Text Decoder
In addition to the audio encoder, we also mapped the text decoder to the Neural Engine so iPhone deployment can achieve isolated utilization of the Neural Engine for energy efficiency and lowest latency.
Moreover, we significantly improved the accuracy-preservation of mixed-bit palettization (MBP) from previous work and generated quantized variants in addition to original float16 versions of both models to reduce memory usage. This is an optional optimization and all Macs are able to use float16 precision for all Whisper variants. Compression is required only for older iPhones running the large-v3 variant given the reduced RAM availability. Since this is not a lossless optimization, we introduce the notion of quality-of-inference (QoI) and calculate it for all compressed variants. You can read more about the results and context behind QoI here.
In addition to memory savings, this compression technique is natively accelerated on the Neural Engine but the latency improvement is significant only for the text decoder because compressed weights lead to acceleration for mostly bandwidth-bound workloads.
With all these optimizations, the text decoder’s latency is between 50 and 100ms depending on the device, enabling us to generate 6-12 text tokens in the remaining 650 ms budget.
Pre-computing KV Cache for Special Tokens
Finally, recall that the first several tokens are special tokens related to language and task settings and are unrelated to the speech content. One could think of pre-computing the required forward passes at compile-time and pre-filling the KV cache instead of recomputing them for each and every audio chunk window. This would let us compute 3 more actual text tokens instead recomputing the special tokens every time. It will also reduce the time-to-first-token latency by up to 3 times the text decoder forward pass latency.
Unfortunately, the KV cache values related to these special tokens are also a function of the audio input which is only available at runtime! Nonetheless, we had a strong intuition that the training objective of Whisper does not induce a strong correlation between the audio embeddings and the KV cache values related to the special tokens due to causal masking and the content independent gradient averages. We tested this intuition by pre-computing the KV cache values for all task and language settings on a batch of random input data (rather than actual audio encodings). We then created a look-up table to fetch the KV cache values instead of running the text decoder during inference.
We validated this approach by rerunning all evaluations and including this optimization under the turbo version of large-v3. The result QoI and WER metrics are unchanged from before!
We also tested a few null hypotheses such as all zeros and simple gaussian noise vectors to pre-fill the KV cache and those failed to generate any meaningful result so we didn't test them further. With this optimization we are now able to afford ~9-15 tokens per 1 second of audio chunk in streaming mode which is fast enough for most of daily speech.
Work Remaining until Stable Release
We are looking forward to your feedback and contributions towards a stable release!
In parallel, we are planning to include at least the following features and improvements before WhisperKit’s first stable release:
Performance Report creation in our example App for trivially reproducible performance results across all devices and model versions and a community benchmark page on GitHub to crowdsource results.
Async batch predictions for single-process high-throughput batch processing. Today’s beta release requires multiple concurrent processes to achieve maximum throughput.
watchOS example app and including test coverage for Apple Watch targets. Source code for this is already in WhisperKit.
Our Metal-based inference engine as an alternative backend to harness the GPU with more flexibility and higher performance.